Bringing energy materials to market using deep learning for natural language processing
Bringing energy materials to market using deep learning for natural language processing
Promotor(en): M. Sluydts, S. Cottenier /20MAT03 / Solid-state physicsProbleemstelling:
The development of new materials is central to the evolution of most technology. For the energy sector, interesting materials are those that generate, store or transport energy. Typical examples are photovoltaics, thermoelectrics and even superconductors. In the case of the company Umicore batteries are one of the prime areas of innovation. While plenty of research is spent refining existing technologies, true breakthroughs may only be found in the discovery of entirely new materials. The experimental production of new materials is however both time-intensive and expensive.
Ab initio techniques make it possible to predict which hypothetical materials exist and even some properties relevant to their performance as energy materials, like the bandgap. Using these techniques, large-scale databases have been created and made public, ready to be mined for the next big energy material. So what’s the problem? Even if we know a material may be stable, we don’t yet know how to synthesize it. At the same time, we also need to know which of the many hypothetical materials will be best for a specific application. While, certain ab initio properties may give good indications of this, not all properties can be calculated in large numbers.
The solution: look through the literature. There are over 3 million scientific articles on inorganic materials, written over many decades. It’s not unreasonable to think that somewhere in this treasure trove of human experience lies to answer to our questions. How do we extract it? For a single material maybe we could try to find the most relevant literature, but for thousands it quickly becomes an impossible task. Using deep learning techniques, nowadays often deep learning, we can automatically process the entirety of scientific literature and extract only the information relevant to us.
Doelstelling:
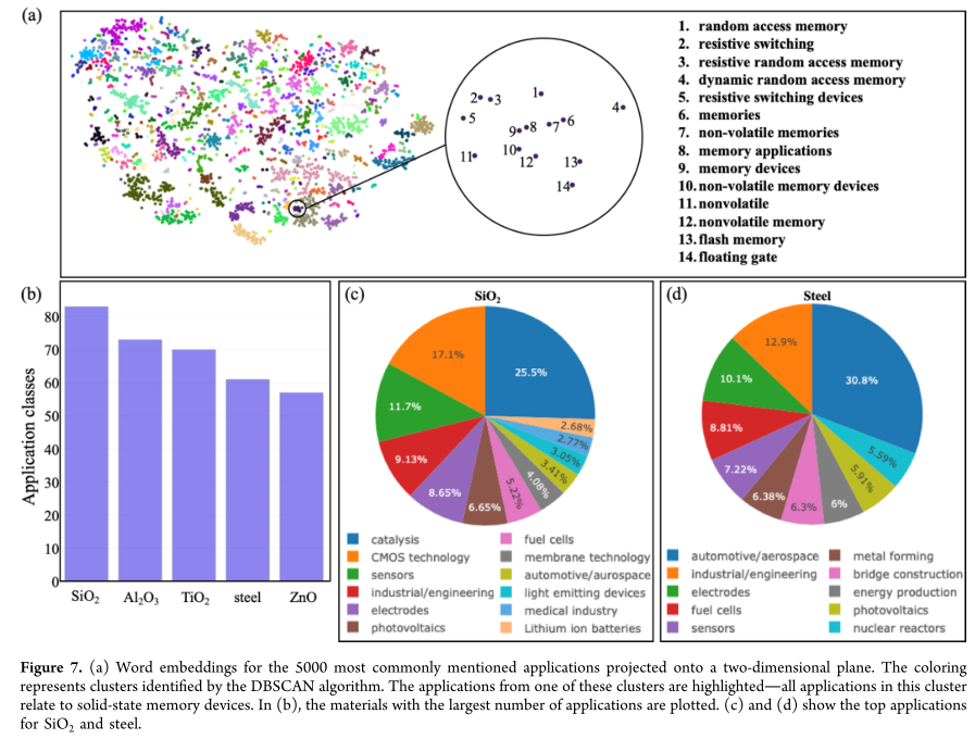
In this thesis, we will use natural language processing techniques to gain insight into the possible synthesis pathways and applications of a large database of new materials previously simulated within the center for molecular modeling. One important tool will be the usage of word embeddings (see figure): high-dimensional vector spaces representing the relation of concepts from the literature. Since materials, synthesis methods and applications live in the same vector space, the distance between points can be directly used to link them. More advanced models can then be used to make a more detailed plan for the synthesis. This research will be in collaboration with the company Umicore, with the aim of exploring the synthesis of battery materials.
Key points:
- Explore our existing in-house database of possible new energy materials and use word embeddings to rank them for applications using the existing Matscholar database.[1]
- Analyze possible synthesis methods for the most promising materials
- From the database, extract which papers the information originated from and make a classifier to predict which future articles will be most relevant
- Use a pretrained deep learning model to predict the full synthesis pathway for the materials and compare with estimations from the ab initio energies [3,4]
- Study programmeMaster of Science in Engineering Physics [EMPHYS], Master of Science in Sustainable Materials Engineering [EMMAEN], Master of Science in Physics and Astronomy [CMFYST]Keywordsmachine learning, energy materials, materials discoveryReferences
Literature:
1. Tshitoyan, V. et al. Unsupervised word embeddings capture latent knowledge from materials science literature. Nature 571, 95–98 (2019).
2. Weston, L. et al. Named Entity Recognition and Normalization Applied to Large-Scale Information Extraction from the Materials Science Literature. J. Chem. Inf. Model. 59, 3692–3702 (2019).
3. Kim, E. et al. Inorganic Materials Synthesis Planning with Literature-Trained Neural Networks. J. Chem. Inf. Model. acs.jcim.9b00995 (2020). doi:10.1021/acs.jcim.9b00995
4. Kim, E. et al. Materials Synthesis Insights from Scientific Literature via Text Extraction and Machine Learning. Chem. Mater. 29, 9436–9444 (2017).
5. Weston, L. et al. Named Entity Recognition and Normalization Applied to Large-Scale Information Extraction from the Materials Science Literature. (2019). doi:10.1021/acs.jcim.9b00470
Contact
Stefaan Cottenier